

{kind=link}
In collaboration with OpenAI, NVIDIA has optimized the corporate’s new open-source gpt-oss fashions for NVIDIA GPUs, delivering good, quick inference from the cloud to the PC. These new reasoning fashions allow agentic AI functions comparable to internet search, in-depth analysis and plenty of extra.
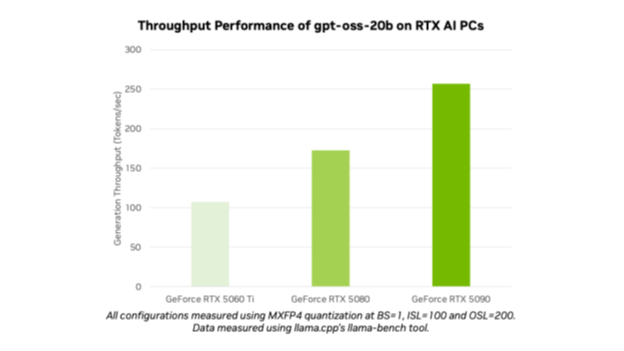
With the launch of gpt-oss-20b and gpt-oss-120b, OpenAI has opened cutting-edge fashions to tens of millions of customers. AI fanatics and builders can use the optimized fashions on NVIDIA RTX AI PCs and workstations via in style instruments and frameworks like Ollama, llama.cpp and Microsoft AI Foundry Native, and anticipate efficiency of as much as 256 tokens per second on the NVIDIA GeForce RTX 5090 GPU.
“OpenAI confirmed the world what might be constructed on NVIDIA AI — and now they’re advancing innovation in open-source software program,” mentioned Jensen Huang, founder and CEO of NVIDIA. “The gpt-oss fashions let builders in every single place construct on that state-of-the-art open-source basis, strengthening U.S. expertise management in AI — all on the world’s largest AI compute infrastructure.”
The fashions’ launch highlights NVIDIA’s AI management from coaching to inference and from cloud to AI PC.
Open for All
Each gpt-oss-20b and gpt-oss-120b are versatile, open-weight reasoning fashions with chain-of-thought capabilities and adjustable reasoning effort ranges utilizing the favored mixture-of-experts structure. The fashions are designed to help options like instruction-following and power use, and have been educated on NVIDIA H100 GPUs.
These fashions can help as much as 131,072 context lengths, among the many longest accessible in native inference. This implies the fashions can motive via context issues, best for duties comparable to internet search, coding help, doc comprehension and in-depth analysis.
The OpenAI open fashions are the primary MXFP4 fashions supported on NVIDIA RTX. MXFP4 permits for prime mannequin high quality, providing quick, environment friendly efficiency whereas requiring fewer assets in contrast with different precision sorts.
Run the OpenAI Fashions on NVIDIA RTX With Ollama
The simplest approach to take a look at these fashions on RTX AI PCs, on GPUs with not less than 24GB of VRAM, is utilizing the brand new Ollama app. Ollama is in style with AI fanatics and builders for its ease of integration, and the brand new consumer interface (UI) contains out-of-the-box help for OpenAI’s open-weight fashions. Ollama is totally optimized for RTX, making it best for shoppers trying to expertise the ability of private AI on their PC or workstation.
As soon as put in, Ollama allows fast, simple chatting with the fashions. Merely choose the mannequin from the dropdown menu and ship a message. As a result of Ollama is optimized for RTX, there are not any extra configurations or instructions required to make sure prime efficiency on supported GPUs.
{kind=link}
Ollama’s new app contains different new options, like simple help for PDF or textual content recordsdata inside chats, multimodal help on relevant fashions so customers can embody pictures of their prompts, and simply customizable context lengths when working with giant paperwork or chats.
Builders may also use Ollama through command line interface or the app’s software program growth equipment (SDK) to energy their functions and workflows.
Different Methods to Use the New OpenAI Fashions on RTX
Fanatics and builders may also strive the gpt-oss fashions on RTX AI PCs via varied different functions and frameworks, all powered by RTX, on GPUs which have not less than 16GB of VRAM.
NVIDIA continues to collaborate with the open-source neighborhood on each llama.cpp and the GGML tensor library to optimize efficiency on RTX GPUs. Current contributions embody implementing CUDA Graphs to scale back overhead and including algorithms that cut back CPU overheads. Try the llama.cpp GitHub repository to get began.
Home windows builders may also entry OpenAI’s new fashions through Microsoft AI Foundry Native, at the moment in public preview. Foundry Native is an on-device AI inferencing resolution that integrates into workflows through the command line, SDK or software programming interfaces. Foundry Native makes use of ONNX Runtime, optimized via CUDA, with help for NVIDIA TensorRT for RTX coming quickly. Getting began is straightforward: set up Foundry Native and invoke “Foundry mannequin run gpt-oss-20b” in a terminal.
The discharge of those open-source fashions kicks off the following wave of AI innovation from fanatics and builders trying so as to add reasoning to their AI-accelerated Home windows functions.
Every week, the RTX AI Storage weblog collection options community-driven AI improvements and content material for these trying to study extra about NVIDIA NIM microservices and AI Blueprints, in addition to constructing AI brokers, artistic workflows, productiveness apps and extra on AI PCs and workstations.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC publication. Be a part of NVIDIA’s Discord server to attach with neighborhood builders and AI fanatics for discussions on what’s doable with RTX AI.
Comply with NVIDIA Workstation on LinkedIn and X.
See discover relating to software program product data.